
you can just say things
using magic words to make a web app more secure

I’ve started to dip my toes into speech-to-text because … well … it’s a vibe, isn’t it?

To say typing is second-nature to me is understating how attuned my brain is to the keyboard. For me the keyboard is an extension of self. In so many contexts it’s how I present to the world.
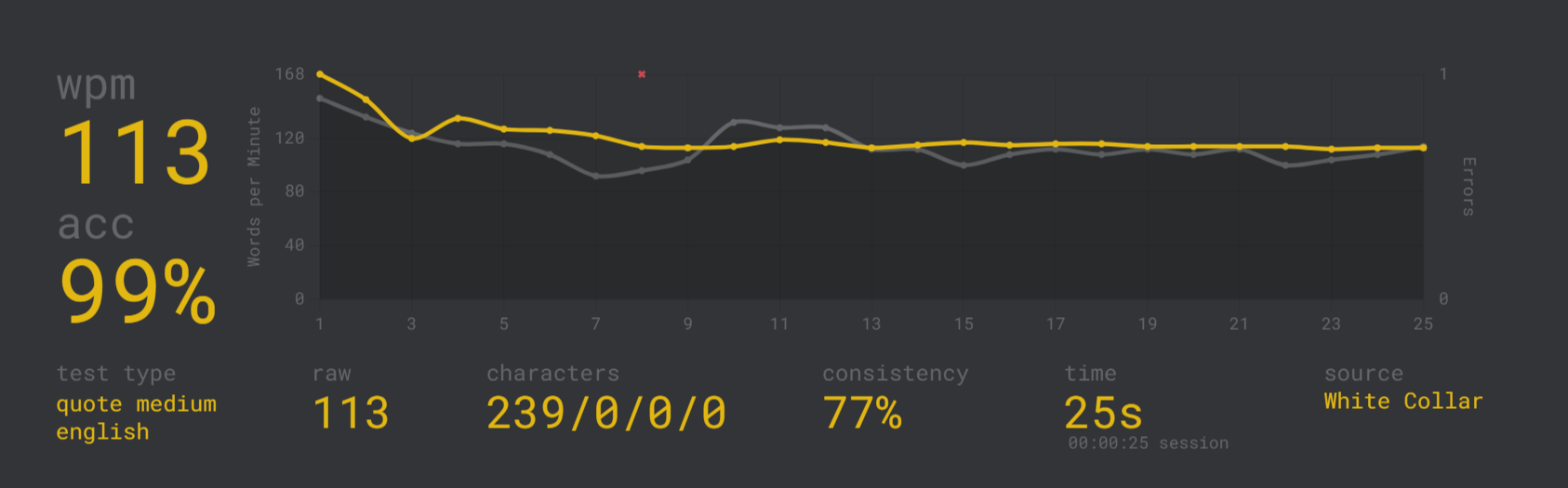
So using anything other than a keyboard to interact with a machine—even a conversational machine—seeks to undo literal decades of training how I outsource my brain to said machine. It seems really unnatural, and there’s something that nags at me that I actually think differently when I speak at a machine than when I type into it. Even still, I’m giving it a shot, and Wispr Flow is currently clocking me at 191 words-per-minute.
Is there some measure of productivity-per-word that forms a more apt comparison between speaking and typing? I don’t know. But it won’t matter much if the future of productivity is all vocal.
make it so, number one
I believe that we’re on the cusp of what I describe as a Roddenberry-esque version of the future.
See, in 1987 Gene Roddenberry turned the Star Trek dial up to eleven by creating Star Trek: The Next Generation about the crew of a starship exploring our section of the galaxy in the 24th century. It had a humanity-centered, utopian mythos and its fair share of highbrow extraterrestrial political intrigue, but what sticks with me more than anything else was its deep integration of technology into life.
For example people routinely used the 24th century’s version of an iPad over 20 years before Apple would launch one in 2010:

But in most situations you would never deign to interact with a computer with your hands. Oh ho no… why use your hands when you can just talk to the machine to use its vast intellect to get information or to get it to do things for you? In what is sure to be the ultimate vibe-coding flex, these spacefarers used something called a holodeck in which they would tell the computer to manifest entire interactive and immersive scenes that could play out as the future’s answer to LARPing1 or to learn something from some long-dead historical figure like Einstein.
Unlike real consumer technology making some of Star Trek’s technology seem weirdly antiquated almost 40 years later, this human-machine interaction pattern using only your voice to manifest changes to reality has always seemed a lot more far-fetched.
Until now.
speak now or…
Driven by a well-produced Claude Code tutorial I’ll reflect on in a later post, I finally succumbed to the pressure of the AI zeitgeist and started to use a couple of I’m-going-to-talk-at-my-computer tools. For whatever it’s worth, so far I’ve tried both Wispr Flow and Monologue but haven’t said enough into either of them to notice a big difference in performance or capability or to have developed a preference.
Regardless, what I set out to do yesterday—and what I actually accomplished—was to limit myself to voice interaction with Cursor to get my little learning companion there to walk me through fixing a couple of simple security alerts from packages I’m using in my app.
This was also something I was forcing myself to do to get over my fear of making changes to my main branch of development while working on a feature branch to implement a contractor list, a low-stakes goal I also accomplished just by going through the motions a couple of times. It’s incredible how much we’re held back simply by being mystified by something.
ANYWAY.
My hands still typed the commands needed to fix the security issues. It’s still important to me to build up some muscle memory as I learn. But talking at the machine was pretty productive and started to feel more natural the more we got into it.
There are a ton of improvements to this and adjacent flows models can and probably will make in the future. For instance the model wasn’t talking back at me, which would have been obnoxious given some of the list of things it was spitting out. A better, more Roddenberry-esque exchange would be the model saying something like, “Here’s a package dependency analysis,” and displaying that in the chat window.
Regardless, speech-to-text worked flawlessly, and the model being a model gracefully rolled with verbal cues that just wouldn’t present themselves in typed messages, like this totally unambiguous and not at all meandering response from me: “Yeah, but in this case, make sure that the… Actually, yeah, go ahead and create the commit.”
It went well enough that I plan to do more of it, and I’m looking forward to spinning up a small app on Replit that I vibe-code completely with my voice. To borrow from Ethan Mollick, this is the worst the voice-to-app experience will ever be, and even today we can just speak things into existence. The holodeck may be closer than we think.